
What is it good for?
Compared to Merkle tree proofs, the proof size is constant.
In the end of this article, we will be able to replace Merkle proofs with KZG polynomial commitments, and our proof will always be constant (48 bytes), regardless of the array size or the polynomial order.
Polynomial commitments via Merkle trees
Recap on polynomials (skip this if you are already familiar with them)
A polynomial is nothing but adding some powers of , combined with some coefficients. It is demonstrated via: . The tradition is, capital letters are for abstract polynomial, for example , in this one, can be anything, it could be the secret key, it could be a random data point, it can be anything. Whereas small letters are for certain values, for example , in this one, will be a certain value (the secret key).
Some examples:
The polynomial can be anything. For example: , which can be also expressed as:
or can be: , which can be also expressed as:
notice that, even in , there are actually 6 coefficients (0’s are omitted for brevity) → 6, 0, 0, 0, 0, -55
Recap on polynomials (end)
The relationship between data and polynomials:
It is enough to have only coefficients to construct a polynomial. We can treat our data points as coefficients, allowing us to construct a polynomial for our data.
If our data is 6, 0, 0, 0, 0, -55 → then the polynomial will be , or for the shorter version: . There is exactly one and only one polynomial for a specific coefficient set. In other words, there is one-to-one mapping between polynomials and coefficients.
Have some math culture! Mmmhh, delicious:
the formal definition is:
where ’s are the coefficients. For the ones who don’t like math, this mambo-jambo basically means:
- multiply the coefficients with (powers of )
- then add them all together
in the end, we will have a polynomial with a degree of (means, the highest power of will be )
What are polynomial commitments?
This means, we will commit to some polynomial , and then we will claim that at the point , this very polynomial will give the result . In math language, .
The verifier will request a proof that we did not change the polynomial in order to make . In other words, the verifier wants to be sure about the equation will hold for the very polynomial that is selected in the beginning.
To provide a proof to the verifier, we can commit to the polynomial selected in the beginning. How? By calculating the merkle root of the coefficients.
An Example Run of Constructing a Polynomial Commitment using Merkle Trees
Say our
The coefficients are: 5, 1, 0, 6
Now, we will build a Merkle tree out of these coefficients.
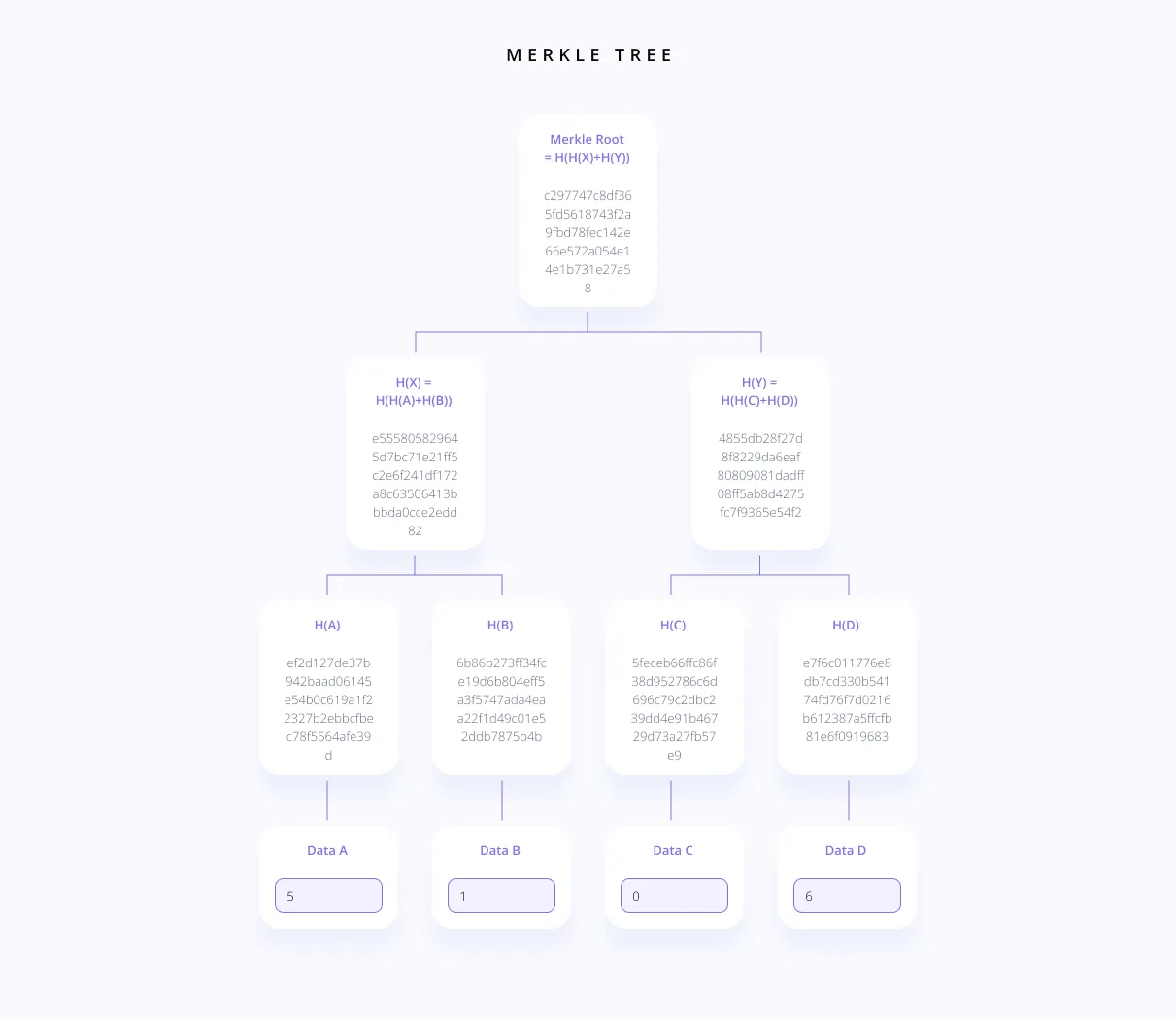 I used this link to generate this image: https://blockchain-academy.hs-mittweida.de/merkle-tree/
I used this link to generate this image: https://blockchain-academy.hs-mittweida.de/merkle-tree/
As the first thing, we will send our commitment (the Merkle root) to the verifier. Then the verifier will give us a value (say, it will be ), and ask for the evaluation for this value for our polynomial. Note that, the verifier does not know the polynomial yet.
Now, say we are the prover, and our claim is , which is correct (we choose not to cheat). But there can be multiple polynomial that can hold the above equation, for example:
We should prove that the equation holds for the original polynomial, which is:
To prove this, we can send all the coefficients to the verifier 5, 1, 0, 6 and the Merkle root: c297747c8df365fd5618743f2a9fbd78fec142e66e572a054e14e1b731e27a58
The verifier will check for 2 things:
- given the polynomial coefficients, she will construct the polynomial, and compute the result herself, and check if our claimed result is matching with what she computed → . If they are matching, good :) If the computed results are not matching, that means someone in this protocol is retarded.
- if the first check holds, then she will construct the Merkle tree for these coefficients herself, and compare our Merkle root provided in the proof, with her Merkle root (which she computed herself). If they are matching, that means we did not change the polynomial!
Why the Merkle root is enough to prove that we did not change the polynomial?
Because: hash functions are not reversible. If we found another polynomial, for which the equation is true → , then we have to send the coefficients of this polynomial to the verifier, and generate a Merkle tree from the coefficients for this polynomial. Recall that we already sent a Merkle root to the verifier as the first step of the protocol, and generating a fake polynomial for which the Merkle root will be equal to the one we sent to the verifier, is practically impossible.
Summary of the protocol:
- prover has a polynomial, he commits to it, and sends to the commitment to the verifier
- verifier has a value, sends this to the prover, and asks for an evaluation for this value
- prover evaluates the value, sends the result, and sends the coefficients of the polynomial
- verifier constructs the polynomial herself:
- computes the result for the value, checks if the prover’s evaluation is the same
- constructs the merkle tree for the coefficients, checks if the prover’s merkle root is the same
Let’s overview the properties of this scheme:
- the commitment was a single element, which is the Merkle root (typically 32 bytes)
- the prover had to send all the coefficients
- the whole polynomial is shared with the verifier, nothing is secret in this scheme
- the data need to be send to verifier is linear: if our polynomial had 1.000.000 coefficients, then we will send 1.000.000 coefficients… In other words, the proof grows as the polynomial grows, this is not very scalable
- the verifier had to reconstruct the polynomial, re-calculate the whole computation
- verifier had to reconstruct the whole Merkle tree
Committing to a polynomial via Merkle trees did not make much sense? Great! Because it… doesn’t… It is silly and inefficient. But it will help us understand what polynomial commitments are, and then we will significantly improve it using Kate Proofs.
What we will achieve with Kate scheme:
- commitment size will be 48 bytes (yeah, 12 bytes larger than before)
- The proof size, independent from the size of the polynomial, is always only one group element. Verification, independent from the size of the polynomial, requires two group multiplications and two pairings, no matter what the degree of the polynomial is. This means, the proof size is constant! UNBELIEVABLE!
- The scheme hides the polynomial (practically: yes; theoretically: not 100%, if the polynomial is very simple, it can be guessed. But it shouldn’t be simple in the first place)
The promises are amazing! Let’s learn how it works.
Combining Elliptic Curves and Secure Multi-Party Computation
In cryptography, we have access to a powerful tool, called secure multi party computation (MPC). It basically allows us to collectively generate a secret (let’s denote this with ). But in the end (here is the good part), no-one will know the secret!
In order to reveal , all the participants would have to collude (they cannot reveal the secret even if all of them are compromised, except one. EVERYONE needs to be corrupted).
Now, the best part is coming: without knowing the value of this secret number (that is why, it is secret), we can actually compute in elliptic curve setting.
How? Well, if you are unfamiliar with basic elliptic curve cryptography, you might need to read the first the parts of this series.
Let be the points on our elliptic curve, and be the generator of .
A generator is a point on elliptic curve, a base point, which, when added to itself generates all other points on the curve. A simple analogy would be 1 for integers: 1+1 = 2, 1+1+1 = 3, and so on, you can get any integer by adding 1 to itself enough times.
Then, is defined as:
In other words, means, is converted to a point in the elliptic curve (it will correspond to one of the points in ).
A good property of elliptic curves is you cannot derive the value of from . After multiplying with , the value of is now hidden. You cannot simply divide with , if you are wondering why, it means you didn’t read the link for ECC (Elliptic Curve Cryptography) up there. Checkmate :)
So, the first thing we will do in our scheme, is to generate a secret number , and then compute
(where is the order(degree) of our polynomial), in an MPC setting. These computed values will be public knowledge, everyone will have access to them. But remember, it is impossible to deduce from these, and also, it is impossible to compute another power of from these: we cannot compute ).
What we can do with these computed values instead, is:
- we can multiply those with a coefficient. Multiplying with will allow us to hide (thanks to elliptic curves)
- that means, we can actually compute .
- by basically multiplying every coefficient with
- going back to one of our examples, our coefficients were:
- so we should compute
-
the whole thing can be shown with:
This means, we just computed the elliptic curve point equivalent of , (which is ), without knowing the secret value .
Kate Commitment
Pronounced kah-tey
In KZG polynomial commitment scheme, the prover first needs to commit to the polynomial (this polynomial will be generated from our data points, for example, our data points can be the coefficients of this polynomial), and then submit a proof , along with his claim . I’ll explain what that all means soon, we will proceed step-by-step.
The point will be selected by the verifier, and sent to the prover after the prover sends his commitment , which is a commitment to the polynomial .
The things that prover needs to know/compute:
- → The prover knows the polynomial , and we showed above how can be computed via an MPC setting.
- → is provided to the prover from the verifier. The prover knows the polynomial itself, this is trivial.
- , the proof → we haven’t talked about it yet. Let’s begin!
Now, the proof is another polynomial, which will help us to construct a relationship with the original polynomial . This will become handy when we want to prove we did not change the original polynomial as the prover. Because remember, we are not using Merkle proofs, and we need a way to prove that we did not change the original polynomial.
And it is time for some polynomial math!
If a polynomial has a zero at point , that means the polynomial is divisible by the term . Being divisible by the term means we can write the following:
for some other polynomial . And this equation is clearly evaluates to zero at the point .
An example:
- (let this be our polynomial)
- (and we find a number that makes our polynomial evaluate to 0)
If you are confused on step 4 and 5, we can divide polynomials using 2 different methods, one of them is by simple division (1), the other one is by factorization (2).

Coming to the crucial part:
- we want to prove
- we know will be zero at the point
- in other words, we know divides
-
what we have is:
- we can compute the polynomial now (as shown above).
- can be anything, so let it be
-
we now have the following relationship:
- or another way to display this relationship:
We cannot work directly with this relationship, because both the prover and the verifier does not know What do they know is, .
This relationship itself can be the thing that will convince the verifier. Why? Let’s see (skip this part if you are not interested in the proof):
- we already committed to via , this commitment is ensuring we cannot change . Reason:
- Let’s assume otherwise. Say for another polynomial , we arrive at the same commitment, which means . And that means . Then, we will be able to cheat by changing with . Now, we should prove that finding should be practically impossible.
- For two different polynomials, we can write the following: .
- We know is not a constant polynomial in this case (a.k.a. it’s order is not 0). How? Because if were to be a constant polynomial, that would have meant the only difference between and is the constant term. So something like below: notice that, between and , the only difference can be and , and it should be in order to to be a constant polynomial.
- But, in that case, we cannot have . It is a contradiction.
- so, is a non-constant polynomial (has some terms in it with in it).
- Polynomial math fact: any non-constant polynomial of degree can evaluate to zero at most different points.
- Recall the prover does not know the secret value .
- So, in order to have , the prover’s best shot is to make in as many places as possible.
- Since , and say order of is . The prover can make in at most points.
- recall:
- which means, this whole thing will ultimately evaluate to a point in the elliptic curve we selected
- recall:
- which again means, this whole thing will ultimately evaluate to a point in the elliptic curve we selected.
- To make , means the generated points on the elliptic curve should be equal.
- Some of the setup parameters are → for the polynomial order, and for the curve order (curve order means, the point amount on the curve).
- Recall the prover’s best shot is to make in as many places as possible (which is points).
- So the attacker would have possibilities in his hand to cheat.
- But the possibility of having the same point on the elliptic curve for for a single trial, is around .
- Ultimately, the attacker has approximately chance, which is
- For reference, finding a collision in SHA256 is:
- Means, finding is around times harder than finding a collision in SHA256… Wow!
- now that we proved cannot be changed after being committed on, let’s inspect the other parts of this relationship →
- cannot be changed, since the verifier herself send it, she would know…
- cannot be changed. Why?
- assume otherwise. The prover wants to cheat with another value .
- recall ,
- then, (remember, )
- the prover needs to divide with in order to find .
- But the prover cannot divide with , since .
- if the prover can find a fake , such that , then he can have the following relationship:
- which is equivalent to ,
- which is equivalent to , which will hold :)
- but this cannot be done, since the attacker has to know about to compute . As long as is kept secret, we don’t need to worry about this.
Finalizing our proof with Kate Commitment
Let’s recall our relationship:
And remember, we cannot work directly with this relationship, because both the prover and the verifier does not know What do they know is, . And seems like that is enough!
The proof evaluation will work as the following:
is our proof .
What we’ve done is, we used values to turn our equation into points in the elliptic curve.
So if we multiply with , and check that if equals to , we should be good to go for this scheme! And remember, all these are points on the elliptic curve.
However… there is one issue… we cannot multiply elliptic curve points :’)
To simulate this multiplication, we will use something called pairing.

Elliptic Curve Pairing in a nutshell
Pairing is an abstract definition, which will help us to multiply (kind of) two different elliptic curve points. A very basic (and probably wrong) summary could be useful to make it more tangible for our brains:
where Q and P are some points on the elliptic curve, and O is an integer (or a complex number) in the multiplicative group. Basically, we “multiplied” Q and P, and get a result of O.
Feel free to treat this as a black box and skip the next section if you are not a math nerd. Otherwise, below is a more elaborate explanation of pairing, enjoy!
Pairing (math warning! skip this if you want to treat it as a blackbox)
Pairing is a bilinear mapping.
What is a bilinear?
Linearity (the property of preserving linear combinations) exists for 1d functions such as , if that function obeys:
For 2d functions such as , the linearity attribute can exist for one dimension, or the other, or both. If both, then the function is said to be “bilinear”
What is bilinear mapping?
In mathematics, a bilinear map is a function combining elements of two vector spaces to yield an element of a third vector space, and is linear in each of its arguments. In plain english, we define a function that is taking two elements from different space, and producing an element in another third space.
Coming back to pairing:
This is a pairing:
Pairing is an abstract operation. Abstract, because the definition can vary. There is Tate pairing, Weil pairing, Ate pairing, and so on… Each of them defining the pairing via different operations.
However, the format of the input and output, and the properties of the pairing is fixed.
- Input: 2 points ( and ) on 2 subgroups of the same curve ( and ).
- is a subgroup of points for the elliptic curve, which in the form , and both and are simple integers ( )
- is another subgroup of points for the same elliptic curve above (points satisfy the same equation as ), but both and are elements of supercharged complex numbers ( ). and are in the format of
- Output: an integer (or a complex number) in the multiplicative group of order .
In a crypto setting pairing should embody the following properties:
- (this is actually the same as above, I wanted to include it for verbosity)
- (simply, coefficients are interchangeable, because it is
bilinear).- Notice that the coefficients are turning into exponents here if they move out of the parenthesis, unlike remaining as coefficients in the regular
bilinearitydescription I gave above. The reason is, in the regular description, the inputs to the function, and the result, were all in the same format (they were assumed to be defined as an additive group). However, in here, the inputs are elliptic curve coordinates (which are additive), and the result is in format (a multiplicative finite field). To further explain, a multiplication operation for an additive group, is the same as an exponentiation for a multiplicative group. If you felt like this is too much math, unfortunately I agree… - I’ve encountered some other notations on this, in which, and are also defined as multiplicative groups. So the property turned into this: . In short, this is some notation difference and it does not matter as much.
- Notice that the coefficients are turning into exponents here if they move out of the parenthesis, unlike remaining as coefficients in the regular
- (non-degeneracy property)
- additionally for cryptography → we also want this operation to be computable in an efficient manner.
Coming back to Kate proofs
Recall: Let be the points on our elliptic curve, and be the generator of . Then, is defined as → . In other words, converts to a point in the elliptic curve (corresponding to one of the points in ).
Now we change it as the following:
- Let and be two different subgroups of the same elliptic curve
- be the generator of , and be the generator of ,
- Then, is defined as →
- And, is defined as →
- Lastly, lets define our pairing , where is the multiplicative target group
Of course, from the secret value , now two different sets will be distributed, one for , and one for
Verifier should now check the equality of:
which is equivalent to
to which, we are very accustomed to by now :)
Verifier is able do the computations:
- is provided to verifier from the prover
- is selected by the verifier
- the verifier can compute , since she has access to , and computing is equal to computing
- is provided to her from the prover
- she also knows the value (sent by the prover)
- is public
- pairing function is public
The full workflow:
- using a MPC setup, the secret is generated, and using this secret value, two sets will be distributed publicly, one for , and one for . The secret is then discarded forever.
- the prover selects a polynomial, and commits to it: , using , and sends this to the verifier
- verifier asks for the evaluation of the committed polynomial at point
- prover sends the following to the verifier:
- verifier checks the equation:
- if equation holds, verifier accepts the proof
- if equation does not hold, verifier rejects the proof
We just showed how to prove an evaluation of a polynomial at a single point, using only one element as the proof! Using Merkle proofs, we would have to send all the coefficients to the verifier to prove that
Batch-proofs (multi-proofs)
We can go even further! Let’s show how to evaluate a polynomial at ANY number of points and prove it, using still ONLY ONE element.
Say we want to prove the evaluation of points:
Using an interpolation polynomial, we can find a polynomial of degree less than , that goes through all these points. Using Lagrange interpolation, we can compute this interpolation polynomial. I know this may sound advanced, and it is. Google and YouTube will be your friends for understanding how Lagrange interpolation works.
The formula for computing the interpolation polynomial is as follows:
Since our original polynomial is passing through all these points, the polynomial will be zero at each:
Thus, this polynomial will be divisible by:
So we define our zero polynomial as:
Using the zero polynomial, we can again establish a similar relationship that we did before:
We now define the Kate multi-proof for the evaluations of the points:
Notice that our proof is still a single element!
Some differences in this scheme:
- the verifier needs to compute and
- for computing these, she is going to need the points.
- she also will compute and
- for computing these, she needs the sets and
The equation the verifier needs to check is as the following:
which evaluates into:
And via this, we just proved the evaluation of ANY number of points on our polynomial, again providing a single element as a proof!
Kate as a vector commitment
It is actually quite easy to convert Kate polynomial commitment into a vector commitment. And via doing this, we will achieve the following:
- instead of sending hashes to prove a single element belongs to the vector, we will send only one element!
- our proof will consist of only one element, regardless of the vector size!
Here is how:
Previously, we were creating a polynomial using our data points as the coefficients. Now, we will do something different: say we have the elements:
And say is the polynomial that will evaluate to these elements as the following: .
So, for example, to reach , we will plug in the value to our . We know there always is a polynomial that is passing though the points we like. Again, Lagrange interpolation will help us:
Using this polynomial, we can prove the presence of ANY number of elements in the vector using a SINGLE element!
p.s. thanks to Dariia Porechna for reviewing and contributing to this!
Resources:
- https://dankradfeist.de/ethereum/2020/06/16/kate-polynomial-commitments.html
- https://hackmd.io/@tompocock/Hk2A7BD6U
- https://vitalik.ca/general/2017/01/14/exploring_ecp.html
- https://en.wikipedia.org/wiki/Bilinear_map
- https://math.stackexchange.com/
- https://crypto.stackexchange.com/

{kind=link}